Elassandra - large scale multi-datacenter elasticsearch
Elassandra is a GitHub project that integrates Cassandra and Elasticsearch. Elassandra takes the advantages of both and combines them to provide the ability to have a distributed, highly available multi-datacenter search and secondary index data store.
This projects goals are almost identical to the DataStax Enterprise Search features that do the same integration but instead with Solr and Cassandra. Solr is a very similar full text distributed search project built using Lucene (Elasticsearch also uses Lucene). Both Solr and Elasticsearch are very similar in capabilities. DSE Search started from a similar beginnings when T Jake Luciani created Lucandra later named Solandra before working at DataStax and the project becoming an officially developed and supported product.
I have been involved in building both 500 and 1,000 node DataStax Enterprise Search clusters and from experience I can say this combination works extremely well. These systems queries over 100 billion records responded in under a second for complex queries and usually if caching played nicely for simpler queries under 100 milliseconds. In both cases both systems could have been improved to have even better response times. I can see a lot of potential and a bright future for Elassandra considering Elasticsearch is a popular alternative to Solr. However Elasticsearch is fairly weak at providing scale and resiliency. In my experience managing an Elasticsearch cluster under 100 nodes is more time consuming than a 1,000 node Solr+Cassandra (DSE) cluster.
To understand why the integration of Elasticsearch and Cassandra is attractive and how they can compliment each other we must first understand what strengths and weaknesses each bring to the table.
Scale
Cassandra clusters are known to be in the thousands of nodes across multi-datacenters while Elasticsearch clusters are in the hundreds of nodes in a single datacenter. In Elasticsearch the number of shards limits write throughput. With Cassandra adding nodes increases both write and read throughput.
Data retrieval
Cassandra is a fairly primitive store when it comes to how queries work. Recently secondary indexing capabilities have been added which has added a lot of new functionality but their abilities are limited in comparison to what a Lucene based service like Elasticsearch or Solr can provide. By integrating Elasticsearch with Cassandra it enables a very rich set of features for querying data stored in Cassandra.
Data distribution
Both Elasticsearch and Cassandra are distributed data stores. A cluster of nodes handle distributing the data during write operations. During reads data gets aggregated by selecting a group of nodes that represent the full set coverage. This allows you to scale out and add capacity. You can improve performance, resiliency and storage space by adding more nodes. How the two systems distribute data is on the surface similar by partitioning the data but the details of how they do it is very different.
How Elasticsearch distributes data
Elasticsearch has the concept of an index. An index represents a searchable secondary index. Elasticsearch partitions indexes into shards so that it can split large indexes between multiple nodes in the cluster. If you have a 5 terabyte index with 5 shards, each shard would be 1 terabyte in size. For resiliency or read scaling an index can have a replication factor applied so that there are additional copies of each shard on other nodes in the cluster. If a node goes down any shards on that node are still available on other nodes. Each shard has a primary and N replicas.
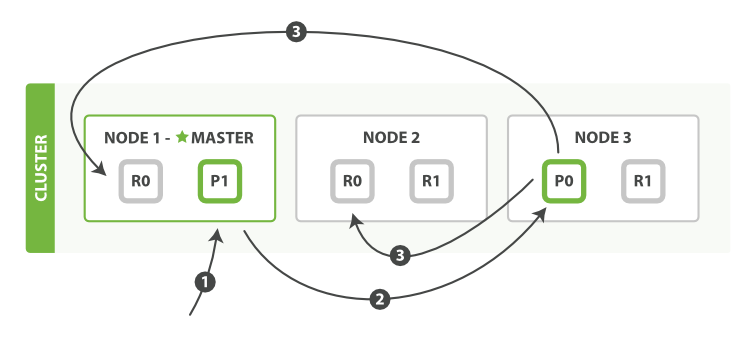 source: elastic.co
source: elastic.co
How Cassandra distributes data
Cassandra uses a DHT (distributed hash table) to partition at a record level. Each node in the cluster (sometimes called the ring) has an assigned collection of vnodes. A vnode is a range slice of the distributed hash table. This means each node stores records that hash to any of the vnode ranges it is responsible for. Each rows row id gets hashed with a hashing algorithm and the resulting hash is an address in the DHT and that points to the node responsible for the vnode range that the row id hash falls into.
Replicas get stored on nodes in a clock wise fashion starting from the primary. This gives predictability to locate data. The hashing algorithm points to a location in the DHT which points to a vnode that exists on a node. If that node is down, you walk clock wise to the next node in the ring.
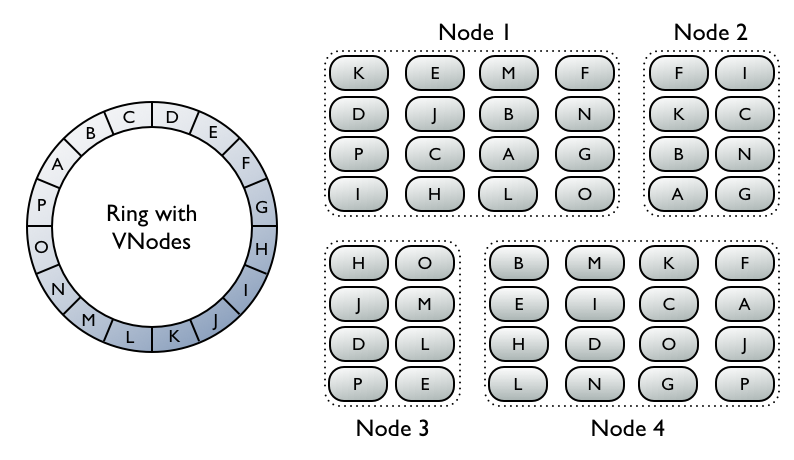 source: datastax.com
source: datastax.com
The key difference here is Cassandra’s unit of distribution is at the row level using a DHT while Elasticsearch uses shards that are large partitions of an index.
Replication
Since Cassandra is primarily (but not only) an eventually consistent data store the replication techniques implemented in Cassandra have far more forgiving requirements on latency and failures. Cassandra is designed with multi-datacenter replication in mind. The replication techniques implemented in Elasticsearch are opposite of that of Cassandra’s and they do not work smoothly over WAN’s between multi-datacenters. Most organizations have to create a customized solution (like Kafka) to replicate Elasticsearch data between datacenters because the built in replication isn’t suitable.
Anti-entropy
Scale is not the only advantage data distribution offers. Resiliency is a key quality that can be added by combining replication with data distribution. This allows the system to handle faults. Nodes go down or become unreachable (partitioned) and never return or are unreachable temporarily for short periods of time or longer durations. These eventually consistent systems use anti-entropy techniques to ensure replicas are up to date as efficiently as possible.
How Elasticsearch handles anti-entropy
This is one of Elasticsearches weaknesses. The anti-entropy techniques used in Elasticsearch are less advanced and less efficient than that of Cassandra or some other distributed data stores. Elasticsearch stores checksums associated to files on disk. This allows replica nodes to compare checksums when a node faults or is unreachable and returns. If the checksum does not match a synchronization happens to update the missing changes. The problem is this checksum can be comparing large files and because a small number of records have been updated a large, sometimes multi-terabyte synchronization occurs transfering duplicate data between nodes instead of a finer grained synchronization containing only the updated changes. You can increase the shard count on an index to reduce this but in the end the checksum technique is still less efficient than other techniques that I will get into later.
I’ve seen Elasticsearch clusters re-synchronize nearly 100GB of data when a node was down or unreachable for less than 15 minutes. This creates significant impact in the cluster and it’s hardware resources.
How Cassandra handles anti-entropy
Each Cassandra node stores merkle tree’s which are a hash tree.
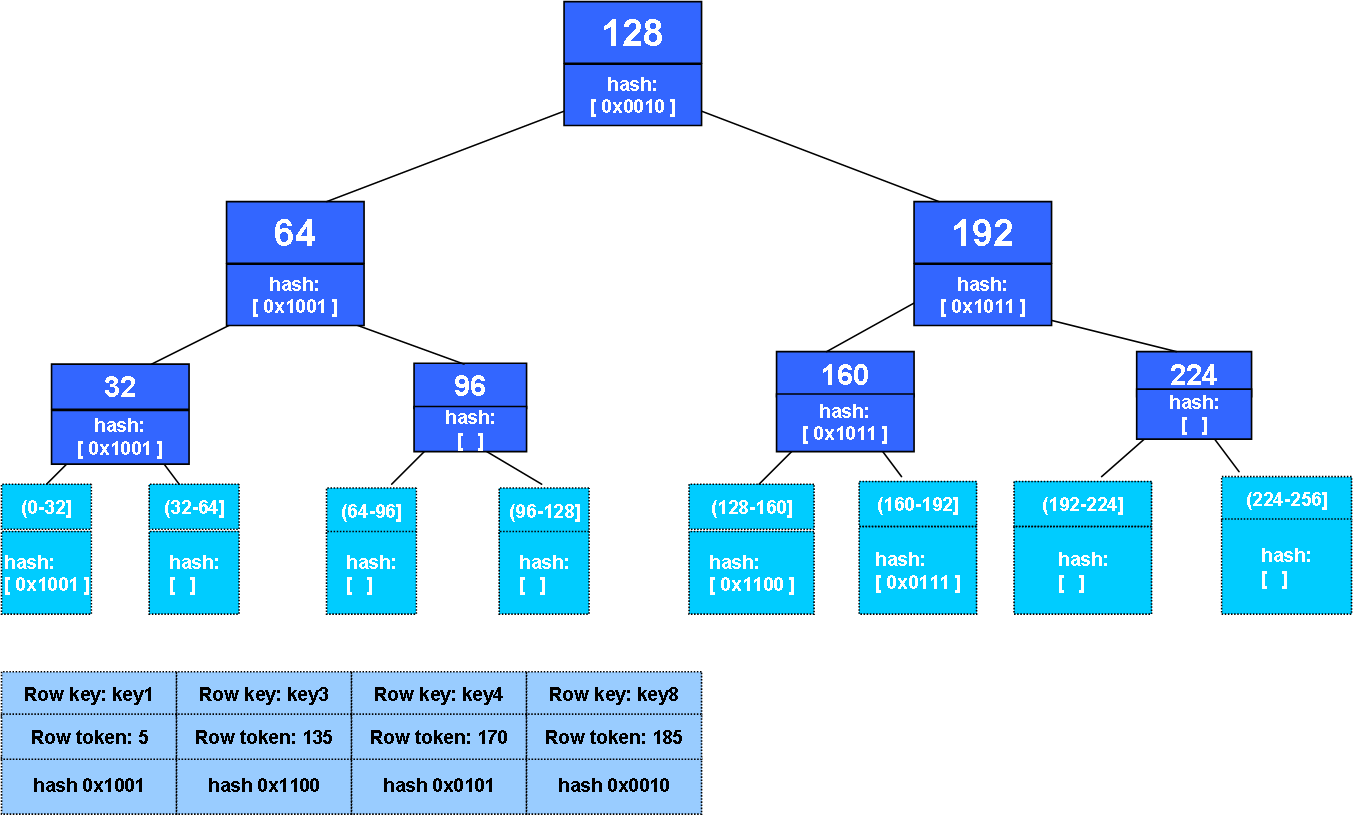 source: distributeddatastore.blogspot.ca
source: distributeddatastore.blogspot.ca
The hash tree allows 2 nodes to compare their hash tree at each tree level until a hash doesn’t match to pin point what records have changed. The drawback is building or storing the merkle tree has a cost but the gain is in the synchronization of changes between nodes. This is a much more advanced and efficient approach than what Elasticsearch does with checksums. This greatly reduces transferring unnecessarily large amounts of unchanged data. This reduces the impact on all nodes involved and reduces the impact on the network.
Resiliency
Elasticsearch is a master designed system while Cassandra is a masterless designed system. Elasticsearch suffers from split-brain while Cassandra does not. Elassandra uses Cassandra’s Paxos transactions during cluster state changes which increases the resilency of Elasticsearch.
Elasticsearch shard re-allocation
Both Elasticsearch and Cassandra replicate data to increase resiliency so that data exists on more than one node. This makes the data available even if one of the replicas fails. How Elasticsearch and Cassandra handle the event of a node failure is different however. For examples sake lets consider that both an Elasticsearch cluster and Cassandra cluster have 4 total copies for each shard or vnode. In the event of a node failure the available replicas will drop to 3. Elasticsearch will do what is called shard re-allocation to source other replicas and bring the replica count back up to 4. This creates a lot of network traffic and disk usage on the remaining nodes. This is problematic for capacity planning, availability and response times. Each remaining node has had a sudden increase in data stored on disk and in memory. If your Elasticsearch cluster is showing signs of wear and is in need of more nodes the event of a node failure may send the cluster into a really bad state and you may start to experience GC pauses, higher response times and request timeouts.
On paper the dynamic behaviour of shard re-allocation during node failures that Elasticsearch does sounds like a good idea but in my experience it has always created an even worse situation across more nodes than the individual node failure should be causing.
The purpose of having N-replicas is so that you can survive F-failures. Cassandra uses a static replication factor. If you lose a node the total copies of data will go from 4 to 3 and stay that way until the node returns or you remove the node from the cluster permanently. Transient failures won’t cause unexpected and sudden impact in the way Elasticsearch does.
The key is to pick the right replication factor that suits how many failures you feel comfortable sustaining. Once that is chosen you can build a cluster that performs properly and you can more easily capacity plan because you won’t experience these sudden changes when a node fails.
Zero downtime
With Elasticsearch re-indexes and mappings changes cause temporary downtime. Elassandra doesn’t suffer from down time during either by taking advantage of Cassandra’s features.
Final thoughts
Cassandra is one of the few rare solutions you can take off the shelf and create a system that scales in the thousands of nodes but it’s not visibly proven to me that Elassandra enables a capable thousand node search cluster. Cassandra does replace several weaknesses in Elasticsearch’s distributed implementations which makes it easier to operate, more efficient and capable of scaling to larger clusters than vanilla Elasticsearch however Cassandra cannot improve Elasticsearch’s query coordination if any implementations show wear at that kind of scale.
Even with that in mind, I think Elassandra has great promise and leveraging Cassandra’s features can make Elasticsearch clusters easier to scale to larger clusters, easier to operate and improve availability with zero downtime operations and multi-datacenter replication.
Remi Trouville and the Elassandra core developer Vincent Royer will be talking about Elassandra at the 2016 Cassandra Summit.